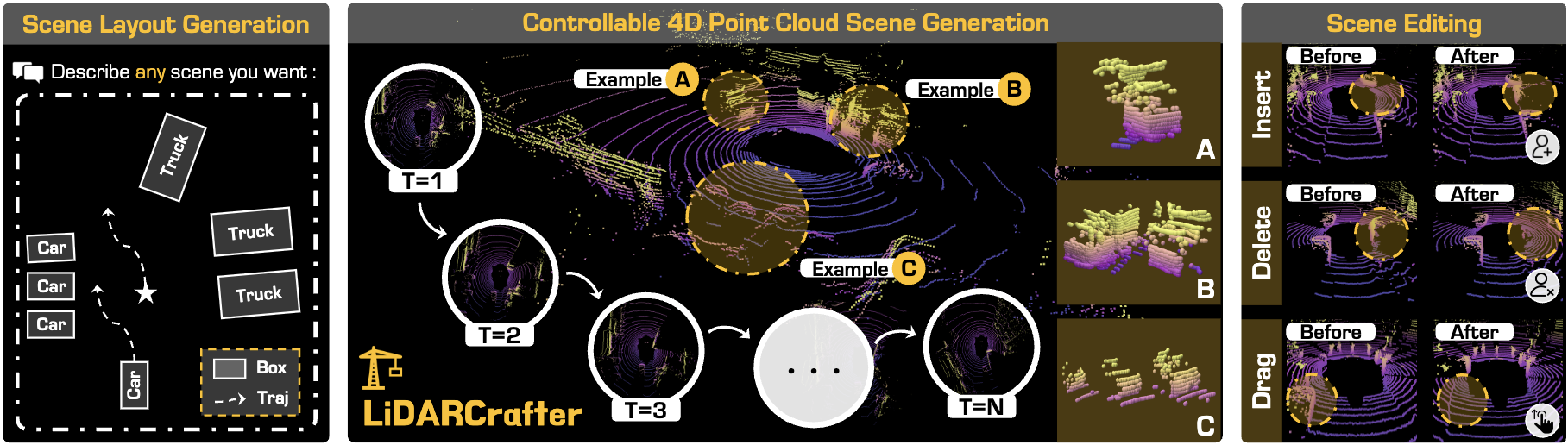
We propose LiDARCrafter, a 4D LiDAR-based generative world model that supports controllable point cloud layout generation (left), dynamic sequential scene generation (center), and rich scene editing applications (right). Our framework enables intuitive "what you describe is what you get" LiDAR-based 4D world modeling.
Generative world models have become essential data engines for autonomous driving, yet most existing efforts focus on videos or occupancy grids, overlooking the unique LiDAR properties. Extending LiDAR generation to dynamic 4D world modeling presents challenges in controllability, temporal coherence, and evaluation standardization. To this end, we present LiDARCrafter, a unified framework for 4D LiDAR generation and editing. Given free-form natural language inputs, we parse instructions into ego-centric scene graphs, which condition a tri-branch diffusion network to generate object structures, motion trajectories, and geometry. These structured conditions enable diverse and fine-grained scene editing. Additionally, an autoregressive module generates temporally coherent 4D LiDAR sequences with smooth transitions. To support standardized evaluation, we establish a comprehensive benchmark with diverse metrics spanning scene-, object-, and sequence-level aspects. Experiments on the nuScenes dataset using this benchmark demonstrate that LiDARCrafter achieves state-of-the-art performance in fidelity, controllability, and temporal consistency across all levels, paving the way for data augmentation and simulation. The code and benchmark are released to the community.
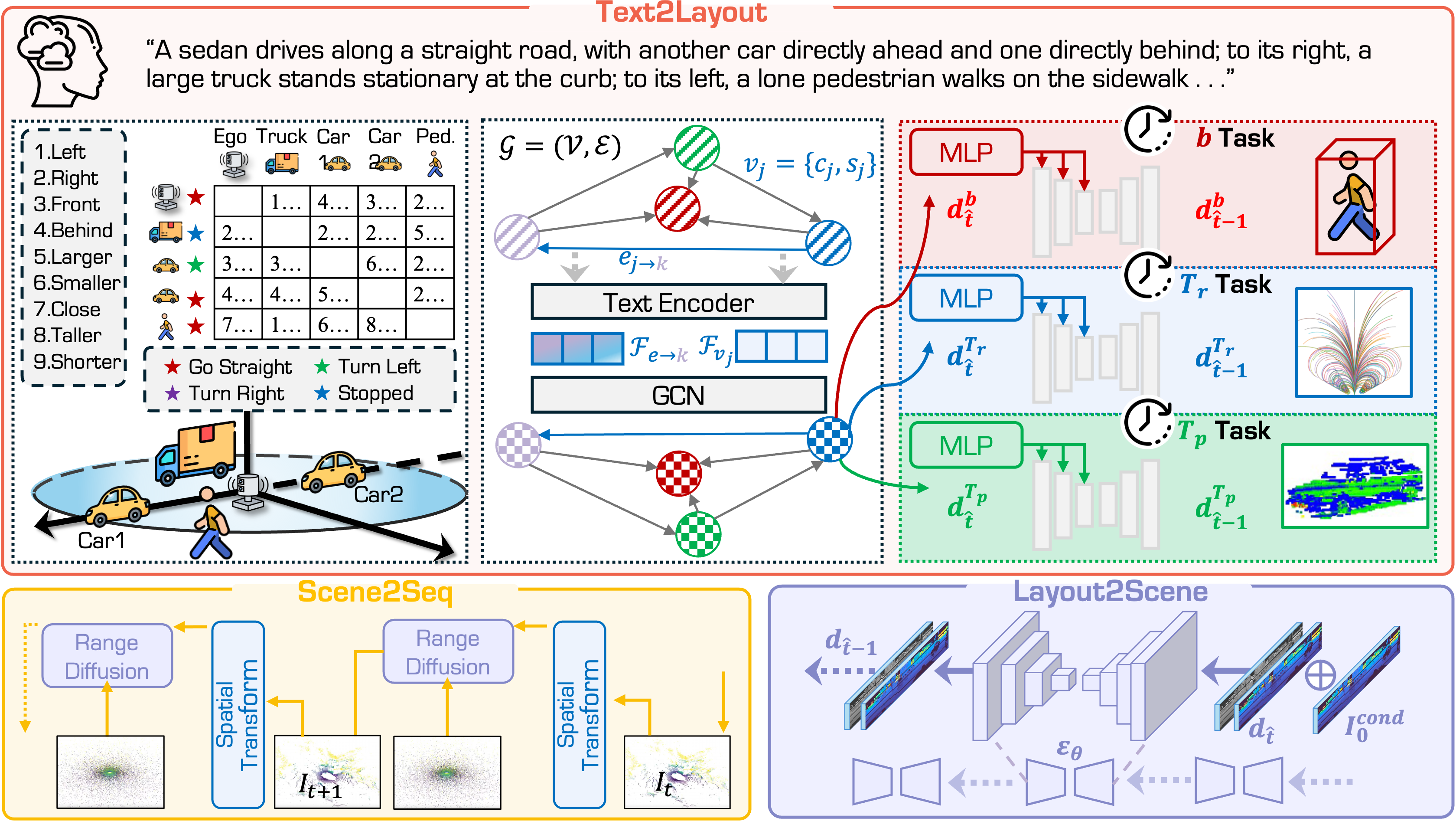
Framework of LiDARCrafter. In the Text2Layout stage, the natural-language instruction is parsed into an ego-centric scene graph, and a tri-branch diffusion network generates 4D conditions for bounding boxes, future trajectories, and object point clouds. In the Layout2Scene stage, a range-image diffusion model uses these conditions to generate a static LiDAR frame. In the Scene2Seq stage, an autoregressive module warps historical points with ego and object motion priors to generate each subsequent frame, producing a temporally coherent LiDAR sequence.
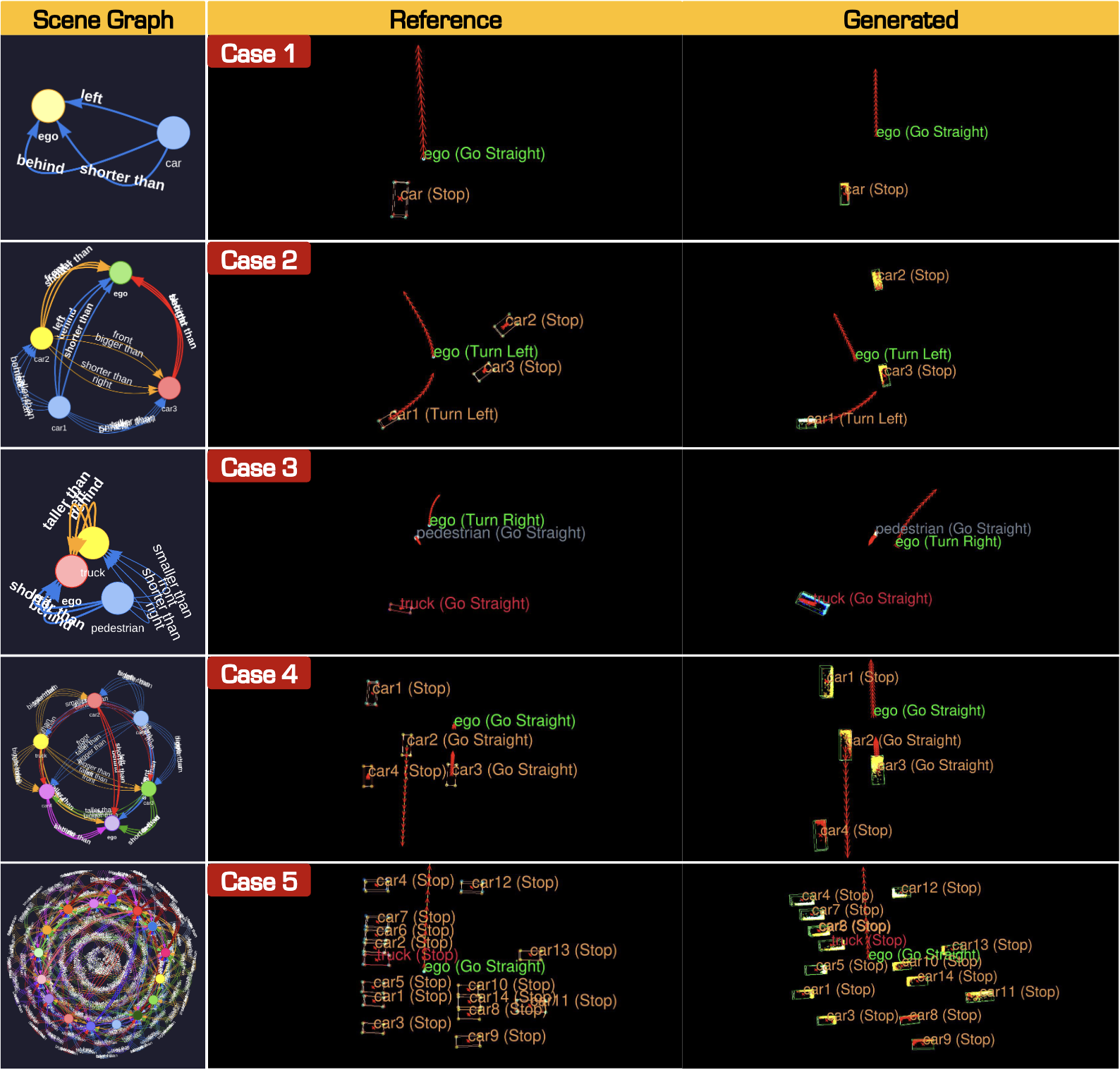

 LiDARCrafter: Dynamic 4D World Modeling from LiDAR Sequences
LiDARCrafter: Dynamic 4D World Modeling from LiDAR Sequences
 4Zhejiang University
4Zhejiang University